Dexterity from Touch: Self-Supervised Pre-Training of Tactile Representations with Robotic Play
Summary
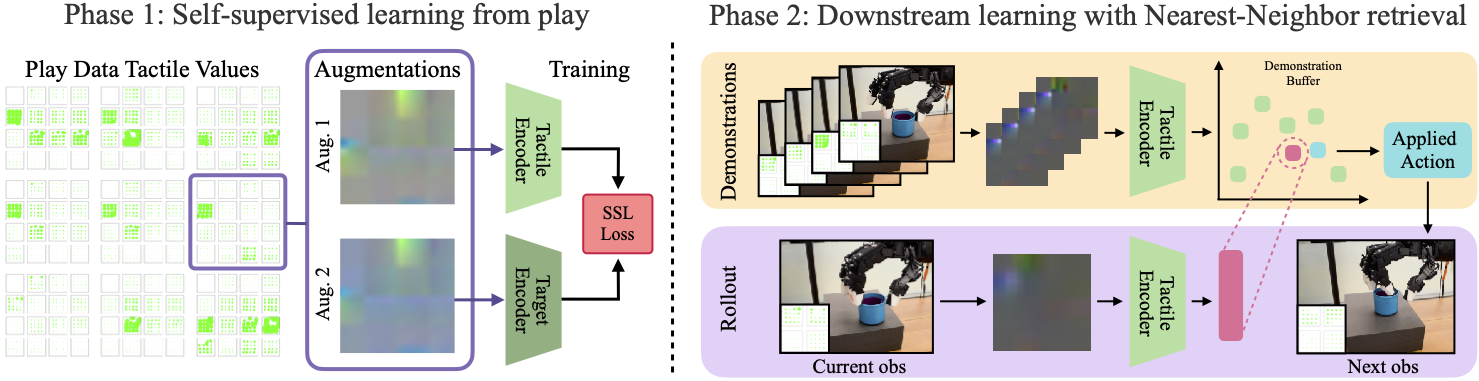
In this work we present T-Dex, a new approach for tactile-based dexterity, that operates in two phases. In the first phase, we collect 2.5 hours of play data, which is used to train self-supervised tactile encoders. In the second phase, given a handful of demonstrations for a dexterous task, we learn non-parametric policies that combine the tactile observations with visual ones. Across five challenging dexterous tasks, we observe that our tactile-based dexterity models outperform purely vision and torque-based models by an average of 1.7X.
Policies
We evaluate our framework on several dexterous tasks that are difficult to solve with visual information alone.
Bowl Unstacking
Cup Unstacking
Joystick Movement
Bottle Cap Opening
Book Opening
Generalization
We observe that our tactile-based policies are able to generalize on new objects that are structurally similar but visually different. Our policy also fails in some cases, which is indicated by a red cross.
Cup Unstacking
Robot rollout for cup unstacking task on unseen cups.
Bowl Unstacking
Robot rollout for bowl unstacking task on unseen bowls.
Method
T-Dex consists of two phases: First phase is to collect a tactile play dataset, where a teleoperator collects 2.5 hours of aimless demonstrations. Given this dataset, a tactile encoder is trained using a self-supervised objective. In the second phase a task-specific policy is acquired by leveraging the pre-trained tactile encoder in the first phase.
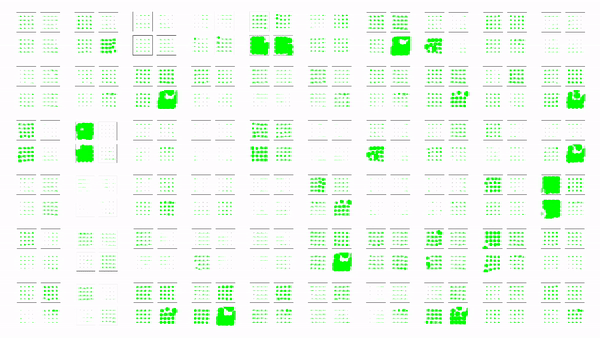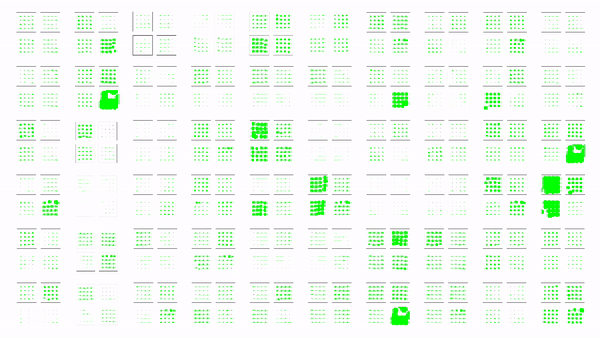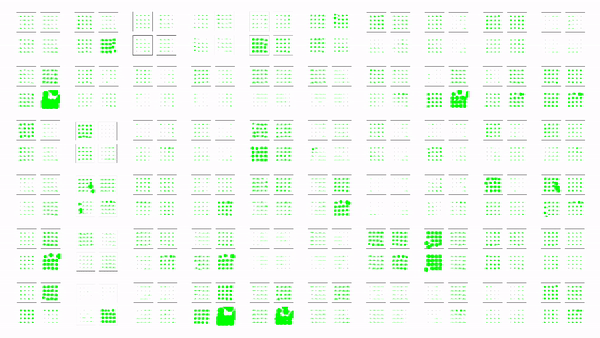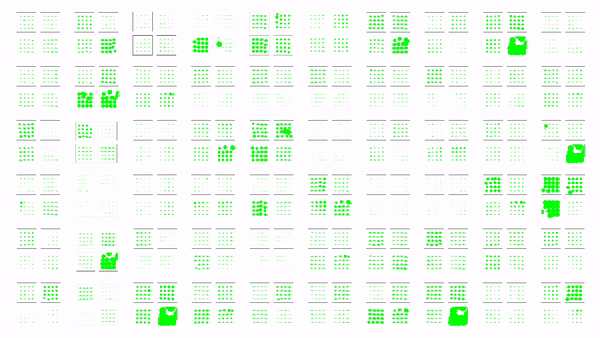
Collected Play Data

Examples of play data collected by a human teleoperator.
Examples of tactile readings from highest activated tactile pads.
Baseline comparisons
We observe that we require both the tactile and image observations combined together to successfully complete our tasks. We show the importance of our method decisions by comparing image only and tactile only neighbor matching policies to T-Dex.
T-Dex
Success: It successfully slides the inner cup.
Image Only NN Matching Policy
Failure: It fails since the policy doesn't know how much force should be applied.
Tactile Only NN Matching Policy
Failure: It fails since the policy doesn't know where the object is.
Bibtex
@misc{guzey2023dexterity,
title={Dexterity from Touch: Self-Supervised Pre-Training of Tactile Representations with Robotic Play},
author={Irmak Guzey and Ben Evans and Soumith Chintala and Lerrel Pinto},
year={2023},
eprint={2303.12076},
archivePrefix={arXiv},
primaryClass={cs.RO}
}
More Rollouts
We show all the robot rollouts and the robot experiments for each of our tasks.